
大型语言模型的突出表现
大型语言模型的规模一直在持续扩大,它在零样本和少样本的环境当中表现优异,能够和经过微调的预训练模型相媲美。比如说在信息提取这个领域,一些模型可以快速且准确地提取特定信息,从而节省人力。然而,在其强大能力的背后,它大规模部署时未经彻底评估的风险也引发了人们的担忧。
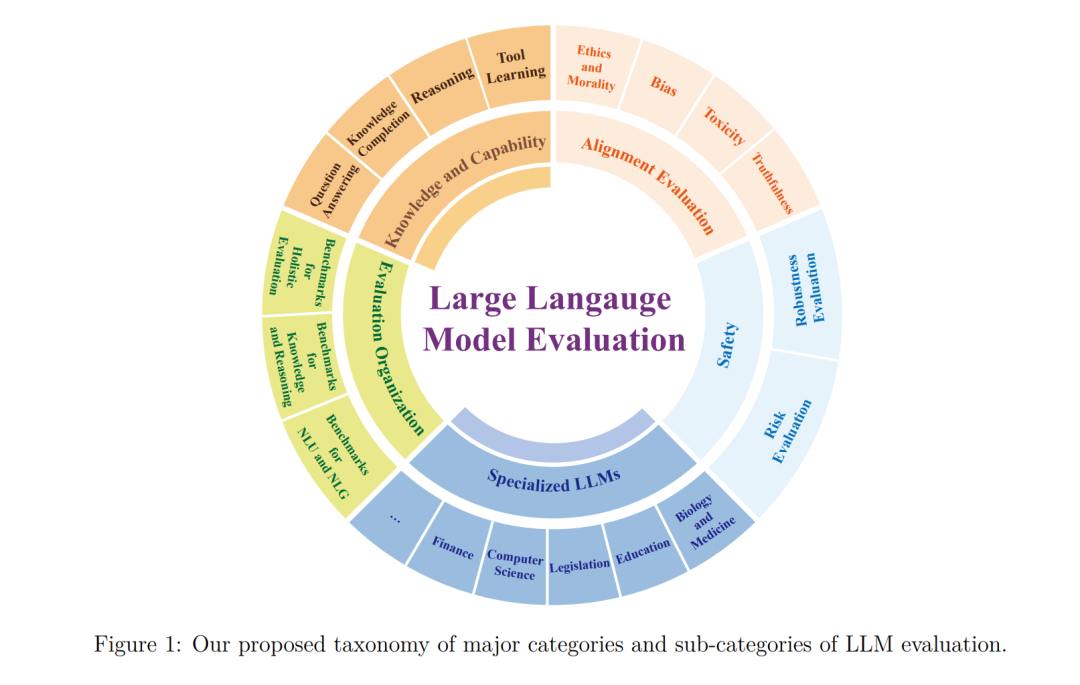
大型语言模型有以放弃训练数据为特点的基准,该基准旨在综合评估模型在零样本和少样本设置下的能力,因而受到行业诸多关注。不过这些基准大多聚焦单一任务或领域表现,存在评估全面性不足的问题。
LLM评估研究的开展
为了回应人们对大规模部署风险的担忧,研究领域出现了专门的方向,这个方向聚焦于实证评估语言模型与人类偏好和价值观的对齐程度。很多调查虽然有侧重点,但是大多只关注单一类别的评估,没有能够整合各类别的见解。
我们的工作会对一般的LLM基准进行总结,也会对评估方法进行总结,这些方面涵盖知识、推理、工具学习、毒性、真实性、鲁棒性和隐私等,会从整合视角给出更全面的描述。
评估手册与平台构建
我们对三个方面的评估方法和基准做了全面调研,还汇编了关于LLMs在专业领域性能的评估手册,手册内容涵盖常见评估指标与方法,能为专业人士提供参考。
同时,要进行讨论,还要着手构建综合评估平台,这个平台要涵盖对LLMs在能力方面的评估,涵盖对LLMs在对齐方面的评估,涵盖对LLMs在安全方面的评估,涵盖对LLMs在适用性方面的评估,以此让评估过程变得更加系统高效。
评估框架的关键价值
评估框架在信息提取领域的发展里起到了关键的作用,它推动了任务的自动化,也推动了智能决策。比如说在金融信息提取工作当中,使用经过评估合格的LLMs能够快速且准确地提取关键数据,进而提升行业效率。
反过来,它促使NLP评估方法不断完善,为研究者提供对比不同系统能力的平台,推动学术研究和商业应用持续发展。
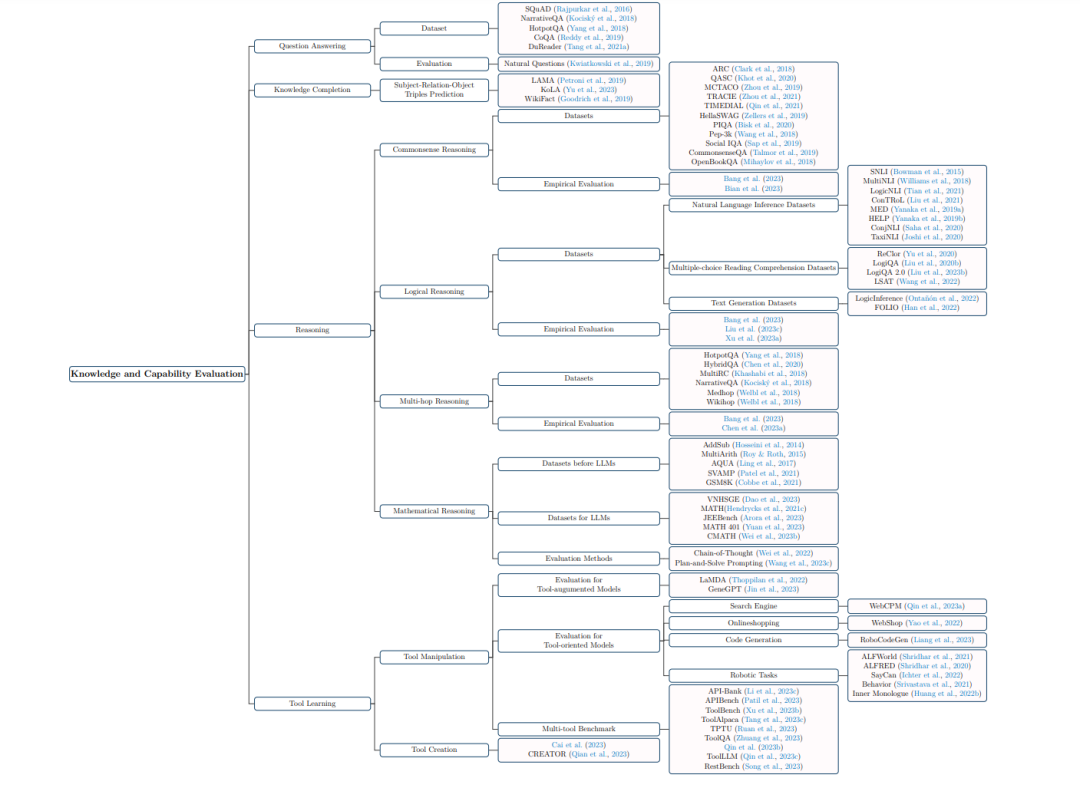
LLM的核心能力阐述
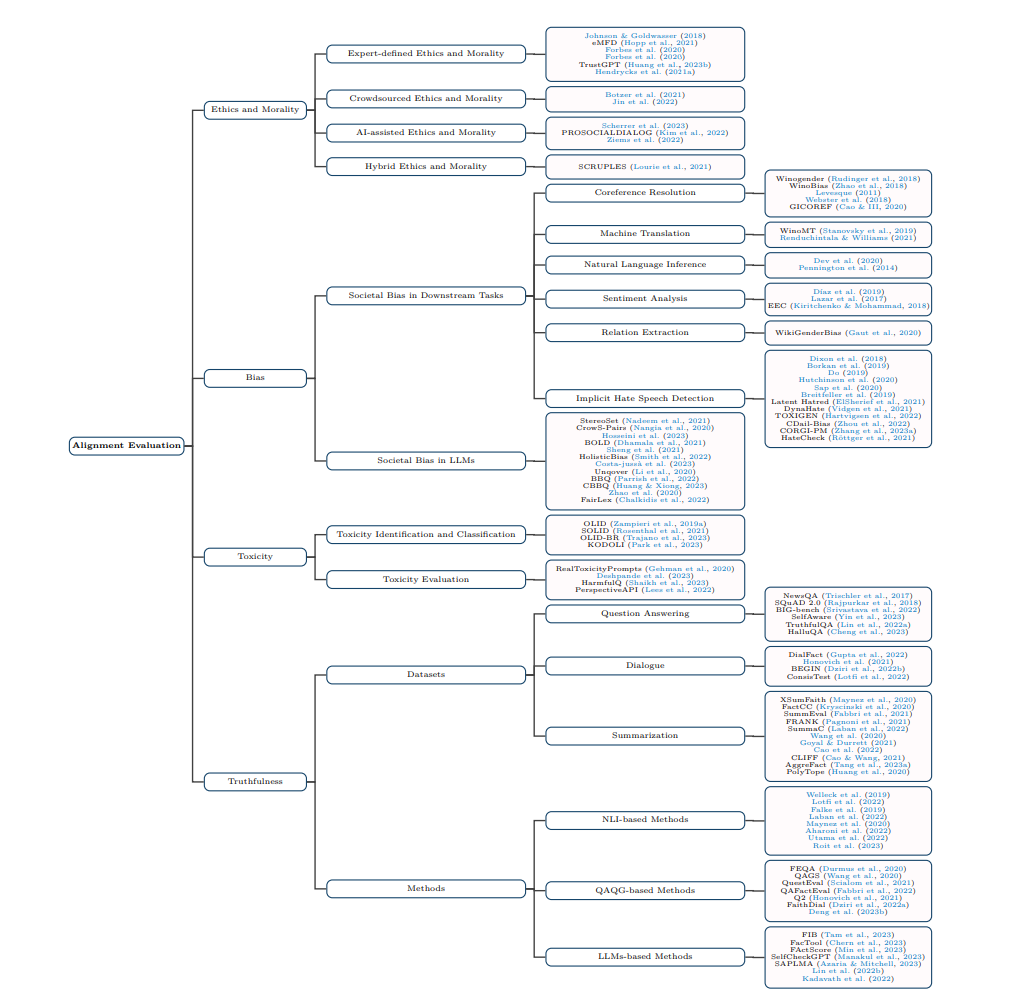
本次调查系统阐述了LLMs的核心能力,其中包括知识和推理能力。在知识方面,模型能够存储大量信息,并且可以准确输出。而推理能力则体现在分析问题以及得出结论上。
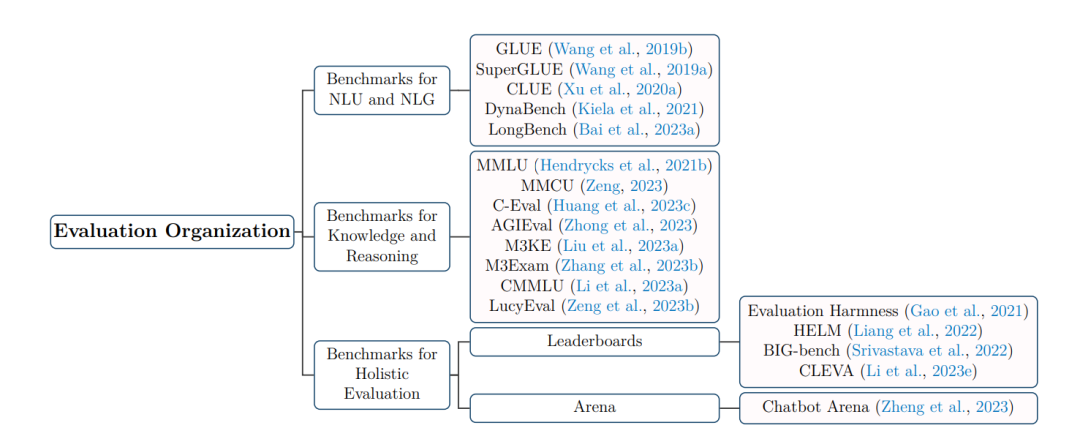
我们提供了一系列基准评估,这些评估很受欢迎,能帮助研究人员理解LLMs性能,能帮助开发人员理解LLMs性能,能帮助从业者理解LLMs性能,还能帮助他们评估LLMs性能,进而让其更好地应用于实际场景 。
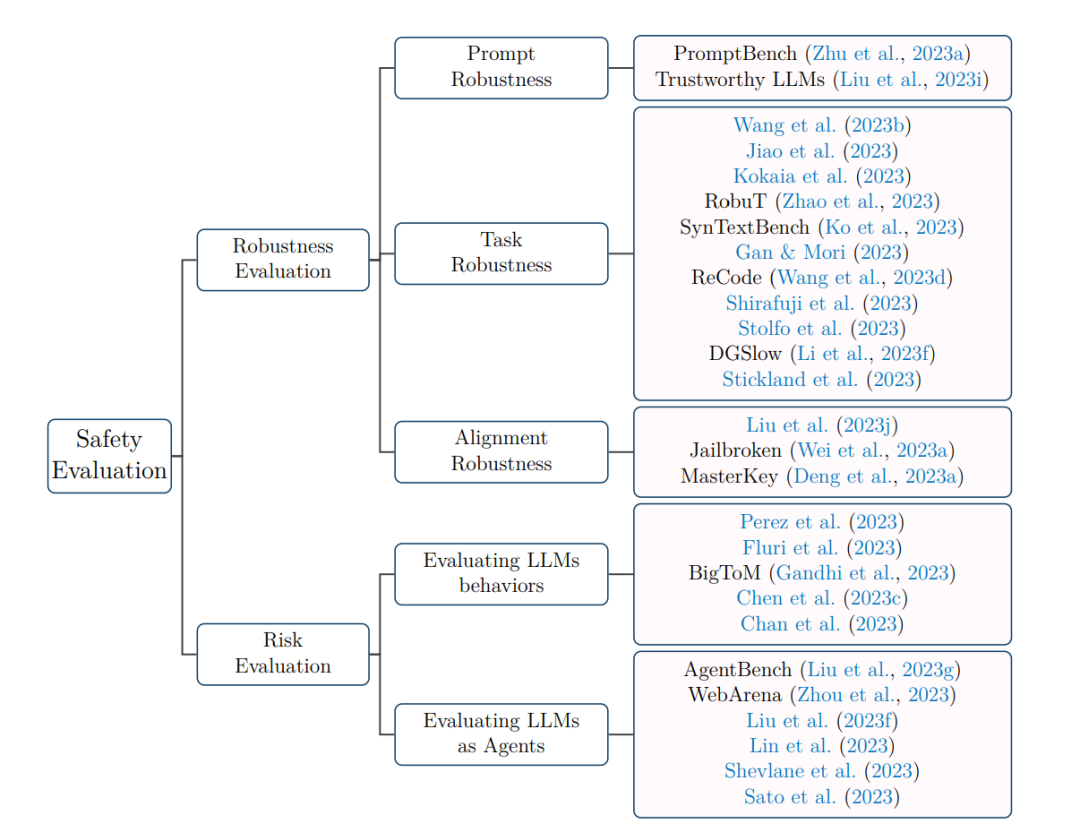
未来评估的发展方向
随着语言模型朝着人类水平的能力发展,评估需要关注更深入的安全问题,要系统评估它面对特定领域挑战时的能力与局限,还要系统评估它面对特定领域复杂性时的能力与局限,以此保障实际应用安全。
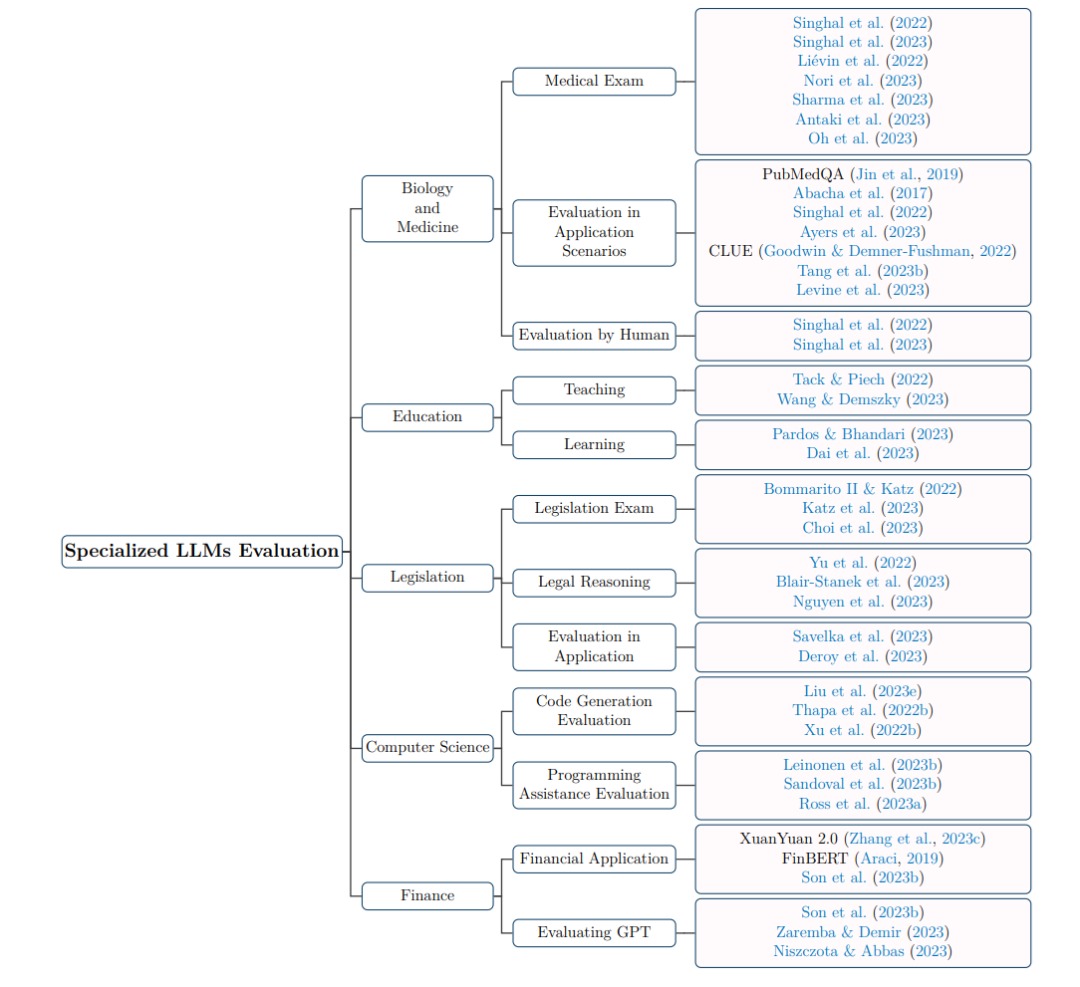
一旦对齐和安全问题得到解决,LLMs能够在专业领域谨慎地进行部署,进而推动各个行业的发展。你觉得当下大型语言模型评估还有哪些急需解决的问题?



发表评论